Basics of the Unicode Standard
History
In the beginning (1960s) there was ASCII, the simple 8-bit character encoding for English. Then other languages joined the Internet, and text encoding standards diverged. ISO/IEC 8859-1 (more commonly known as Latin alphabet No. 1 or simply latin1) was one such standard, but there were many others. Many countries and groups made their own for their languages, and working with text online became more and more difficult.
In the early 1990s, an effort to unify and standardize all the world’s scripts for digital use culminated in the creation of the Unicode Standard, a sort of “One Standard To Rule Them All”. But, we were almost led down a darker path, for another major effort also existed back then, the Universal Coded Character Set (UCS, or ISO/IEC 10646). Luckily (and with no Hobbits involved), the two groups realized that two “universal” standards just wouldn’t work, and the UCS was unified with Unicode. So instead of one of the worst cases of “yet another standard” in the history of computing, we got a truly universal and ubiquitous text encoding standard that is used by nearly everyone in the world today. In this post, I will go over the basics of the Unicode Standard.
Intro
Creating a universal digital text encoding standard for the world is a large and complex problem. Unicode divides it into roughly two areas of concern and tackles them separately:
- The cataloging of all the symbols used in the world’s writing systems. This mostly operates at the linguistic level: what symbols are there, how do they relate to and interact with each other in text
- The digital encoding of all the cataloged symbols. This mostly operates at the level of bits: what exact set of bits do we use to represent (i.e. encode) each symbol so that computers can work with them reliably and efficiently
The distinction between these two parts of the problem has historically been blurred, mostly because some of the popular earlier standards did not separate them clearly1 (e.g. ASCII used both concepts interchangeably). But Unicode made them separate explicitly. The first part of the problem is addressed by the Unicode coded character set, while the second is addressed by the Unicode character encoding forms (of which UTF-8 is by far the most popular encoding form). Let’s take a look at each of them in turn.
The Unicode Coded Character Set
The Unicode coded character set is the foundation of the standard. It is the catalog of almost all the written symbols in the world, and as of the current version of the standard (v13.0 published in 2020), covers 143,859 symbols across 154 different writing systems. Traditional language scripts are not the only ones included in the set. Various other systems of symbols, such as ones used in mathematical and scientific notations, as well as Emojis, are also part of the Unicode set. Whenever you hear on the news that some new Emoji is now part of Unicode, it means that a new version of the Unicode coded character set standard has been published and it added the new Emoji as a symbol in this catalog.
The Unicode character set contains various entries about symbols, each carrying information about a specific symbol in the set (we’ll get into exactly what a Unicode symbol is shortly). This includes some basic information: what the symbol is, its unique identifier in the set, and a short descriptive name for the symbol. It also includes a large amount of properties data on the symbol, specifying what type of symbol it is, its general characteristics, how it relates to and interacts with other symbols, etc… These properties data are what most of the Unicode Standard documents define, and their size (as well as complexity) dwarf the basic symbol data in comparison.
The unique identifier of each symbol in Unicode is called the code point, and it is a number between 0 and 1,114,111, usually expressed in hexadecimal. To make it clear that a number is a Unicode code point, it is typically written with the special prefix U+. So a typical Unicode code point looks like U+0061. The total range of all code point values (from 0 to 1,114,111) is called the Unicode codespace, which is divided into 17 subranges called planes, numbered from 0 to 16. If you’ve been paying attention to the numbers, you probably have realized that most of the Unicode codespace seems unused: there are 1,114,112 possible code points, yet the current standard only contains 143,859 symbols. This is correct, most of the Unicode code space remains unassigned, so there is plenty of room to add new symbols for posterity.
Characters for most of the world’s modern languages all reside in plane 0, the Basic Multilingual Plane (BMP). Plain 0 occupies the first 65,536 values in the codespace (0000 to FFFF in hex), which means that pretty much every symbol you read in regular text has an ID less than 65535. Emojis and many historic scripts (such as Egyptian hieroglyphs) reside in plane 1, the Supplementary Multilingual Plane (SMP).
The basic entry of a symbol in the Unicode character set includes its code point value and name, and looks like this:
a, U+0061, Latin Small Letter A
So what exactly constitutes as a symbol, or character, in Unicode? This is where we have to be reminded of the fact that Unicode is meant to be a universal standard, and so it has to deal with working with all the symbols of the world’s writing systems in a single framework (and preferably without complicating the standard too much). It does this by adopting a highly modular and pragmatic approach, in the spirit of Legos: break down every symbol into its smallest components, define these components as characters, then use a set of composition rules to make all the fancier symbols we need. Let’s get into some details.
For Unicode, the basic symbols specified in the standard are called graphemes, and have a formal definition: they are “the minimally distinctive unit[s] of writing in the context of a particular writing system.”2 Here’s an intuitive example. Every lowercase letter in the English alphabet is a grapheme, as is each of their uppercase counterpart, because letters and their cases both have semantic value in English. But italicized letters do not have semantic value (i.e. no word changes meaning due to its letters being in italic), so they are not graphemes and therefore are not included in the Unicode Standard.
But a grapheme is not always a fundamental building block for other symbols. In Unicode, “fundamental building blocks” are called atomic characters, and it means that they cannot be broken down into further components that are useful. You can think of it as the smallest Lego piece that can still be considered as “a Lego”. The letter “a” is a grapheme and an atomic character, as there aren’t meaningful sub-components of “a”. The letter “á” on the other hand, which is semantically distinct from “a” in a number of languages, is clearly made up of two parts, the plain letter “a” and the acute accent “´” on top. In Unicode, characters like “á” are composite characters, and can be constructed by composing their atomic constituents together. The letter “á”, in this case, is a composite grapheme known as a grapheme cluster, and is represented by the code point sequence U+0061 U+00B4, which is just the code point for “a” (U+0061) concatenated with the code point for the acute accent “´” (U+00B4).
The astute reader might be confused by this point: if you look up the character “á” in a Unicode character table you will see that it has a single code point value, U+00E1, not the composite sequence of code points. The character table isn’t wrong, and this is where the “pragmatic” part of Unicode’s approach comes in. Even though compositions are functionally sufficient to create all the characters we need, they are inefficient to use and implement in practice (plus they also cause all kinds of compatibility problems). So Unicode has given many commonly used composite characters dedicated code points. These are called precomposed or canonical composite characters, and nobody uses the raw composed sequence representation for these characters.
Unicode compositions are very powerful. They allow for many distinct composite characters to be created without overly complicating the core set of characters in the standard. This example from the official specifications illustrates the power of compositions clearly:
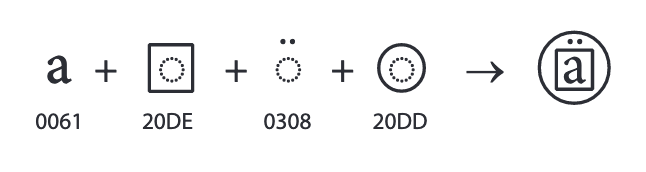
(Note however, even though compositions like this are technically standard-conforming, computer systems may not support and be able to show them correctly, especially for very complex arbitrary composite characters)
To complete the circle with compositions, Unicode defines a corresponding decomposition mapping to take apart composite characters back into their constituent components. To do this, the rules specified in the decomposition mapping is applied recursively to a composite character, until only atomic characters remain. For composite characters that have multiple accents or marks such as “ṩ”, the ordering of the atomic characters in their decomposed forms may differ depending on how the rules are applied. To ensure consistency, Unicode defines a set of normalization forms specifying how atomic characters should be ordered following decomposition. The normalized fully decomposed sequence of a character is called the canonical decomposition of the character.
Decomposition and normalization in Unicode are critical, as they give us information on the equivalence of characters without forcing us to have to merge similar or even identical characters. The character “Å” is one such case. “Å” is a letter in the Swedish alphabet, and its basic character set entry is:
Å, U+00C5, Latin Capital Letter A with Ring Above °
However, “Å” is also the symbol for the angstrom, a unit of length equal to one-tenth of a nanometer. Due to the drastic difference in the context of use (perhaps the length unit will be rendered or formatted differently from just the letter), Unicode has defined the length unit version of the character differently3. Here’s its basic character set entry:
Å, U+212B, Angstrom Sign
So here we have a case where we have a duplicate character that we don’t want to merge due to their different usage contexts. Yet they are visually the same symbol, so we’d like to be able to recognize that they are the same character, for the purposes of ordering, comparing, and searching. We can do this by creating some explicit mapping in the standard, storing this equivalence. But this would quickly get out of hand (as similar cases are not all that rare), and greatly complicate these basic text operations (imagine having to do lookups in some giant character equivalence table every time you need to search text). But with Unicode decomposition and normalization, this isn’t a problem at all. In Unicode, the two characters with code points U+00C5 (the Swedish letter) and U+212B (the length unit) both decompose canonically into the same code point sequence U+0041 U+030A. Through the decomposition and normalization processes, not only do we find out that the two characters are the same, we also learn that they are both based on the plain Latin letter “A” (code point U+0041)4.
Back to the main topic of the Unicode character set. All the rules of composition, decomposition, and normalization are specified in the extra properties data of the characters. Together with some other important information on the characters, they form the highly flexible and powerful system of symbolic catalog at the core of the character set. But something is still missing, namely the bigger picture of how the characters interact with one another. To address these “bigger picture” problems, we can’t just operate at the individual character level. Unicode tackles them by defining a number of holistic specifications covering the entirety of all the characters in the set.
One such problem is ordering, known as character collation. It’s easy when we only have a deal with one system of writing: we know that “a” comes before “b” in English. But things get tricky when dealing with hundreds of scripts. Unicode defines a specification for a sorting algorithm, the Unicode Collation Algorithm (UCA). It uses other concepts in the standard, such as decompositions and normalizations, to make sorting more sensical and easier across different languages. It also includes multiple collations for languages that have different ways to order their characters.
Another “bigger picture” problem is the handling of different writing directions, including mixed directions, Unicode defines a specification for a layout algorithm to deal with this formally, the Unicode Bidirectional Algorithm (UBA). It is an extremely complex specification that is capable of handling text that runs in both directions on the same line (such as in the cases of Arabic or Hebrew text with digits). The algorithm helps to correctly determine the location of punctuations based on the surrounding text, and even has a built-in mechanism to add overrides in situations that are ambiguous from the immediate context.
The last such problem that I will mention here is about semantic boundaries. We know that in English, words are generally separated by spaces and punctuation marks. But this isn’t the case in many other languages. For example, scripts based on logograms (including Chinese, Japanese, and Korean) do not use any visual indicators to delineate words, and instead, rely on language semantics. This makes it tricky to figure out which group of characters form words in many languages. Word boundaries are especially important for computers to know about, because they make working with text a lot easier. Think about how when you double click on a word on a web page, the computer just knows to select the word5. This problem is important enough that Unicode has decided to include these boundary information in the character set standard, even though strictly speaking it isn’t about working with the characters themselves.
To recap, the Unicode coded character set is a catalog of modular, composable characters, each with a unique identifier called the code point, along with a set of specifications defining how the characters interact with each other. Now let’s take a look at how this character set is understood by computers, in the world of bits.
The Unicode Character Encoding Forms
When we move to the problem of representing the characters digitally for computers, we don’t have to worry about a lot of the things from the coded character set. This is one of the benefits of separating the problem this way. In every day computing, we mostly just need to represent and display the characters. How exactly they are cataloged, composed, and normalized aren’t as important here. And so as far as computers are concerned, most tools and libraries that work with just displaying Unicode characters aren’t aware of all the advanced rules and specifications from the coded character set standard.
Computers are mostly concerned with two things when it comes to Unicode: how to encode each character as a sequence of bits (called code units), and how to decode a sequence of bits back to the character for display and processing. These operations are achieved by defining character encoding forms, and by far the simplest and most straightforward Unicode encoding form is UTF-32.
UTF-32 is the original standard encoding form of Unicode, and it simply uses the code point of each character to encode it. Since the code point uniquely identifies a single character, and it is just a number between 0 and 1,114,111, we can simply use the binary representation of the code point value to encode each character. UTF-32 is a fixed-width encoding: it always uses 32 bits to encode the code point value, which of course is way overkill, since even the maximum code point value of 1,114,111 is far smaller than what 32 bits can represent. For example, we’ve seen above that the character set code point for the letter “a” is U+0061. The UTF-32 encoding of the letter is simply the same value, but padded to the full 32 bits: 00000061. Or in binary:
00000000 00000000 00000000 01100001
(Technically this is the encoding of “a” under UTF-32BE, the big-endian scheme of UTF-32. Endianness has to do with the ordering of bytes and which end of the data sequence do the most significant bytes begin at. In UTF-32LE, the little-endian scheme of UTF-32, the order of the bytes would just be reversed, with the non-zero byte on the left)
Decoding a character with UTF-32 is also trivial, since the encoded value equals the code point value. We can simply lookup the encoded value as a hex directly in the Unicode character table, which will give us the character data for display.
If we are just going to use the code point values as the encoding, then there isn’t much of a point to define character encoding forms separately. The character set alone should suffice, as it already assigns unique numeric values to each character. The problem, as you might have already noticed, is efficiency. Being fixed-width, UTF-32 is terribly wasteful. Three out of the four bytes in the example above for the encoding of “a” are completely useless.
The encoding form UTF-8 was created to solve this problem, and it did it so well that it became the de facto standard of text encodings everywhere. UTF-8 has a few very useful characteristics:
- Optimized for space efficiency. If we can use fewer bytes, we will. As a result,
UTF-8is a variable-width encoding, its encoded data can range from 1-4 bytes - Fully compatible with
ASCII.UTF-8uses just a single byte to represent all theASCIIcharacters, and does so identically toASCII. Any validASCIIencoding is also a validUTF-8encoding - No more worrying about byte ordering (i.e. endianness). Unlike
UTF-32andUTF-16,UTF-8does away with byte ordering, and so does not have two variants (one for big-endian and one for little-endian)
As a result, UTF-8 encodings no longer match the literal code point values for many characters, so some actual encoding and decoding logic is involved when working with UTF-8. Here is a couple of examples in hex and binary to show how the various encoding schemes represent characters.
For the letter “a”, with the code point value of U+0061:
UTF-32 Hex: 00 00 00 61
UTF-8 Hex: 61
UTF-32 Bin: 00000000 00000000 00000000 01100001
UTF-8 Bin: 01100001
ASCII Bin: 01100001
For the angstrom symbol “Å”, with the code point value of U+212B:
UTF-32 Hex: 00 00 21 2B
UTF-8 Hex: E2 84 AB
UTF-32 Bin: 00000000 00000000 00100001 00101011
UTF-8 Bin: 11100010 10000100 10101011
ASCII Bin: N/A
Summary
To tie everything we’ve talked about together, here is a high level diagram summarizing the structure of the Unicode Standard:
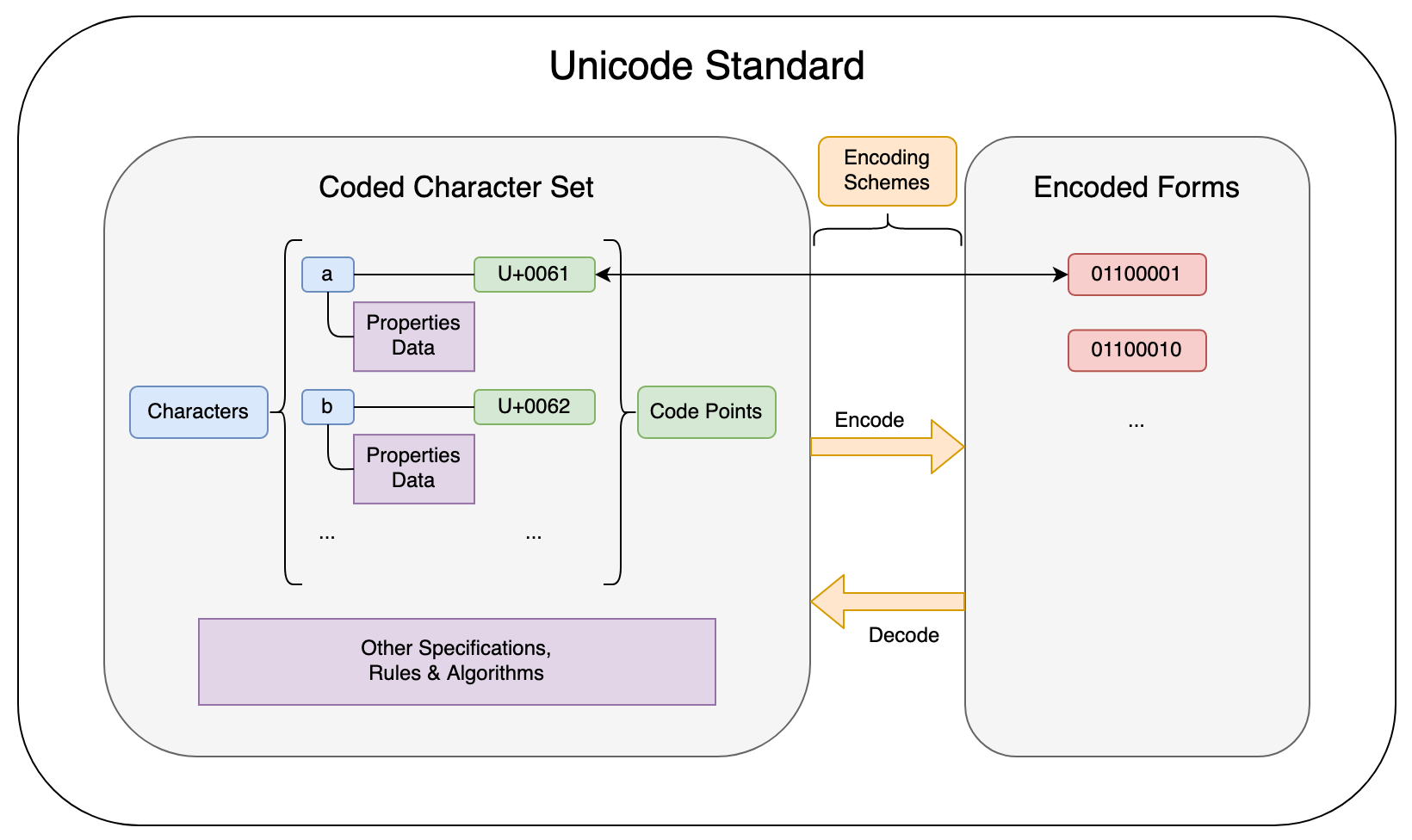
I hope that this has served as a useful basic introduction to the universal text encoding standard of the modern world. To learn more about the inner workings of Unicode, the standard’s official core specification document is quite accessible, and a great place to start.
Some of this confusion is still highly visible today. The
Content-Typeheader in HTTP for example, commonly contains the valuecharset=utf-8, which is technically wrong, asUTF-8is a character encoding, not a character set. ↩︎From the official Unicode Glossary entry for “grapheme”. ↩︎
I wonder how many scientific papers or documents are using the wrong Angstrom symbol because their authors inadvertently copied the Swedish letter instead. There is no way to tell them apart visually, as the symbols are identical, but of course the encoded character value in the document file would be different. ↩︎
Canonical decomposition is how text “folding” works. When searching for text, we often want to ignore character accents and match them as if they are all the same. So search query processors will typically convert, or “fold”, all accented characters to their base character to perform the search. Unicode’s decomposition and normalization rules provide an easy way to do this across effectively all languages. ↩︎
You can try it on a page with some logographic scripts, such as this Chinese Wikipedia page. You will notice that double clicking on a character can result in different numbers of surrounding characters being selected, which correspond to the semantic words in the language. Oddly enough, this language-aware text selection only works on Google Chrome but not Firefox for me. ↩︎